Emphasis: understand the techniques
- What it is
- What problems it can solve
- In which situations we should use them
- Any limitations or requirements to use them
- How to evaluate them
# Supervised v.s. Unsupervised Learning 监督学习和无监督学习
# Supervised Learning 监督学习
infer a (predictive) function from data associated with pre defined targets/classes/labels
从与预定义的目标 / 类 / 标签相关的数据中推断一个 (预测) 函数Example: group objects by predefined labels
根据预定义的标签,对对象进行分组Goal: Learn a model from labelled data (with multiple features) for future predictions
从标记的数据 (具有多种特征) 中学习一个模型,用于未来的预测Outcomes: We know outcomes: the predefined labels
我们知道结果:预先定义的标签Evaluation: error/accuracy, and other more metrics
错误 / 准确性,以及其他更多的指标Data Mining Task: Classification
数据挖掘任务:分类
# Unsupervised Learning 无监督学习
discover or describe underlying structure from unlabelled data
从未标记的数据中发现或描述底层结构Example: group objects by multiple features
通过多种特征,对对象进行分组Goal: Learn the structure from unlabelled data (with multiple features)
从没有标记的数据 (具有多种特性) 中学习结构Outcomes: We do not know the outcomes
我们不知道结果Evaluation: No clear performance or evaluation methods
没有明确的表现或评估方法Data Mining Task: Clustering
数据挖掘任务:归并

| Machine Learning Algorithms 机器学习算法 | ||
|---|---|---|
| Unsupervised 无监督学习 | Supervised 监督学习 | |
Continuous 数值型 |
|
|
Categorical 标称型 |
|
|
# Linear Regression
- We have knowledge: values in y
已知值取自 y - We have factors or features: x variables
有因素或特征:x 个变量 - We need to split data into training and testing
将数据分为培训和测试 - We learned the model from training, and evaluate it on the testing set
从训练中学习模型,并在测试集上对其进行评估 - We do have truth in testing test and predictions for test set, as well as evaluation metrics: RMSE, MAE
在检测测试集和对测试集的预测,以及评估指标上 RMSE,MAE - Have a general problem in supervised learning: overfitting
监督学习有一个普遍的问题:过度适应
# Classification
- Classification
- a supervised way to group objects 一个监督的方式来分组对象
- We must have predefined labels 必须有预定义的标签
- We must have knowledge: we know some instances are labeled by predefined classes/labels/categories
必须有知识:我们知道一些实例是由预定义的类 / 标签 / 类别来标记的
For a Purpose of Prediction 为了预测的目的
- To forecast or deduce the label/class based on values of features
根据特征值预测或推断标签 / 类别 - Let the machines/computers think as humans
让机器 / 计算机像人一样思考
- To forecast or deduce the label/class based on values of features
There are many real world applications
现实世界中有很多应用程序- Financial Decision Making, e.g., credit card application
财务决策 - 信用卡申请 - Image Processing, e.g., face recognition in cameras
图像处理 - 摄像头中的人脸识别 - Computer/Network Security, e.g., virus or attack detection
计算机 / 网络安全 - 病毒或攻击检测 - Information Retrieval, e.g., relevance of a document to a query
信息检索 - 文档与查询的相关性 - Recommender Systems, e.g., rating prediction for Amazon
推荐系统 - 亚马逊的评级预测
- Financial Decision Making, e.g., credit card application
Example - Classification App: Credit Card Application
Terminologies in Classification
分类术语
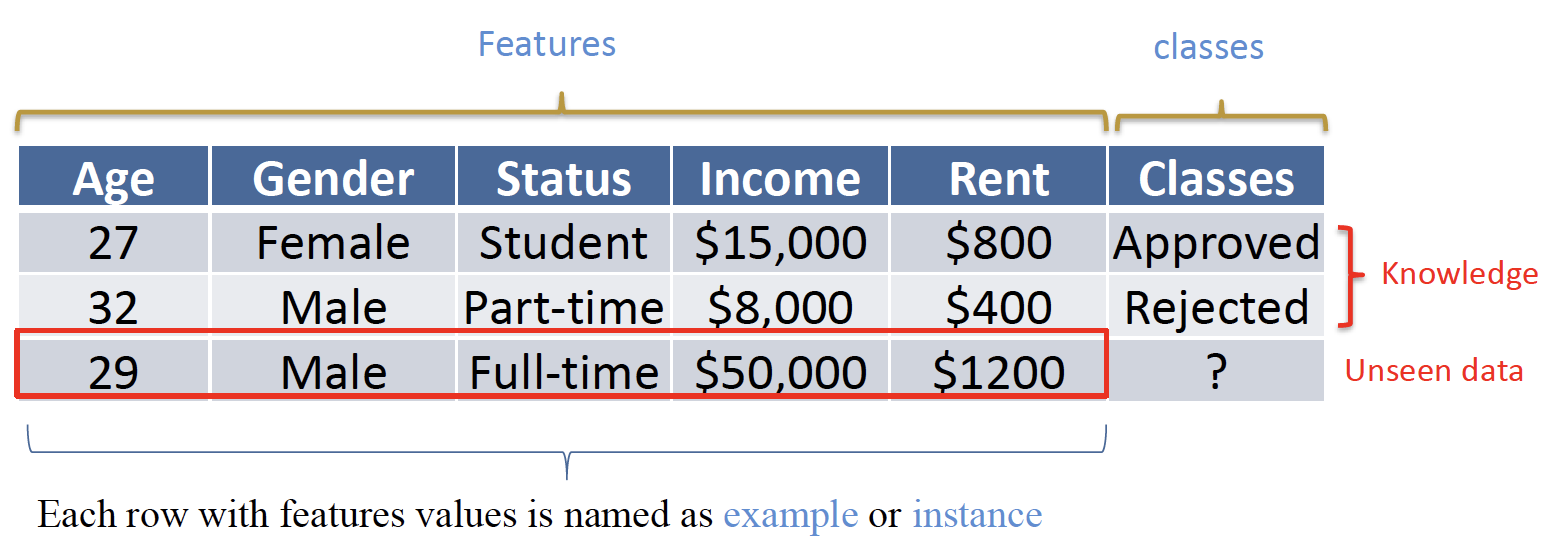
- Features 特征
- Each row with features values is named as example or instance 带有特征值的每一行都被命名为示例或实例
- Classes 分类
- Knowledge 知识
- Unseen data
- Classification
- Learn from the knowledge (examples with unknown labels)
从 knowledge 中学习(标签未知的示例)- build predictive models to predict the unknown examples
建立预测模型来预测未知的例子



# Classification Task 任务
There are usually three types of classification:
通常有三种分类
Binary Classification 二元分类
Question: Is this an apple? Yes or No.
问题:这是苹果吗?是或否。Multi-class Classification 多类分类
Question: Is this an apple, banana or orange?
问题:这是苹果、香蕉还是橘子?Multi-label Classification 多标签分类
Use appropriate words to describe it: Red, Apple, Fruit , Tech, Mac, iPhone
用适当的词来描述它:红色、苹果、水果、科技、Mac、iPhone

We use binary classification as examples to introduce classification techniques.
我们以二元分类为例介绍分类技术。But most of these classification methods can handle multi class classifications too.
但大多数分类方法也可以处理多类分类。There are different strategies to handle multi class classifications.
有不同的策略来处理多类分类。
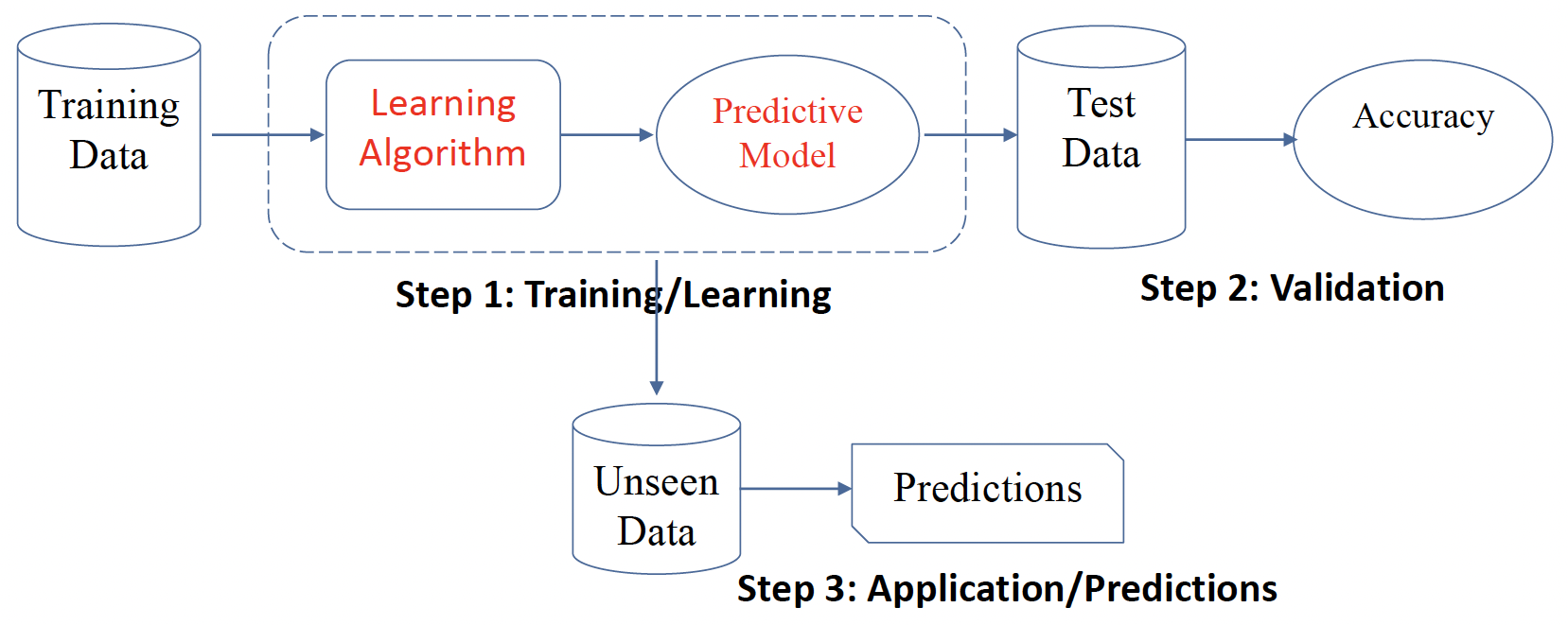
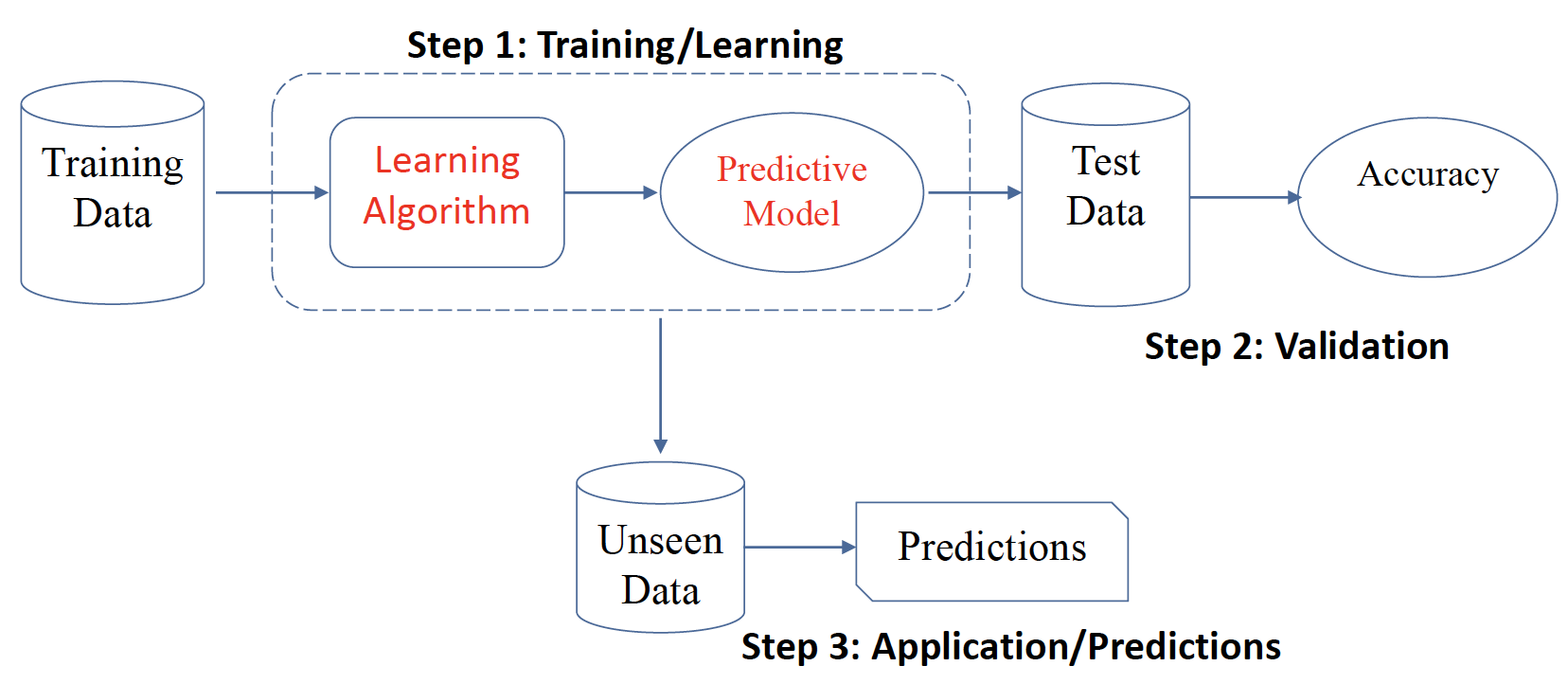
# Standard Classification Process 标准分类流程
- Training/Learning: Learn a model using the training data
训练 / 学习:使用训练数据学习模型 - Validation/Test: Test using test data to assess accuracy
验证 / 测试:使用测试数据评估准确性 - Application/Predictions: Apply the selected model to unseen data
应用 / 预测:将所选模型应用于看不见的数据
# Evaluation 评估
How could we know it is good or bad?
Data Splits for Evaluations 将数据拆分来进行评估
- There are several ways to split your data for evaluations
有几种方法可以分割数据进行评估- Hold-out evaluation
- N-fold cross validation N 倍交叉验证
- Leave one out evaluation
- Stratified N fold cross validation
- ...
# Hold-out evaluation
If your data is large enough
数据足够大的时候使用
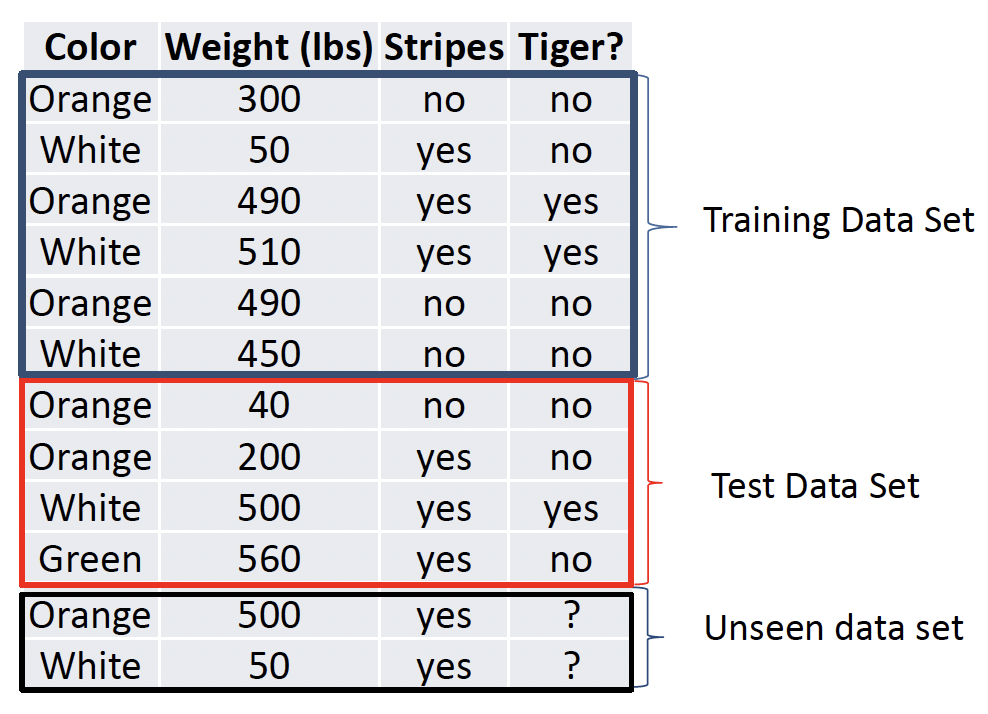
方法一:将 Knowledge 随机分成两部分,一组为 Training Data,一组为 Test Data,通常训练集要大一些 70-80%。
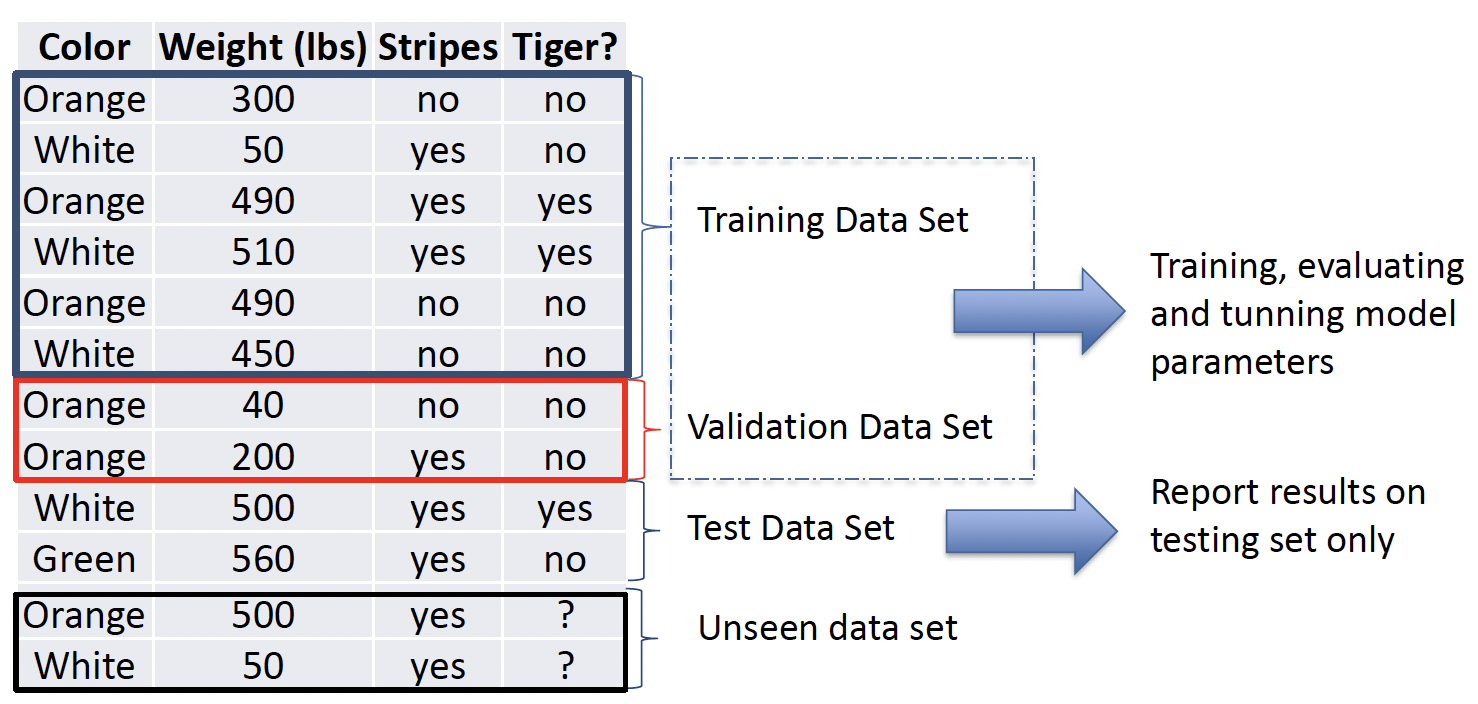
方法二:将 Knowledge 分成三部分,Training Data,Validation Data,用来 Training, evaluating and tunning model parameters,模型参数的训练、评估和调整,以及 Testing Data,Report results on testing set only 仅在测试集上报告结果。这种情况下可以用 Validation 和 Test 两组数据进行评估,最终报告仅基于 Testing data,结果更可靠。
# N-folds Cross Evaluation N 倍交叉验证
If your data is relatively small
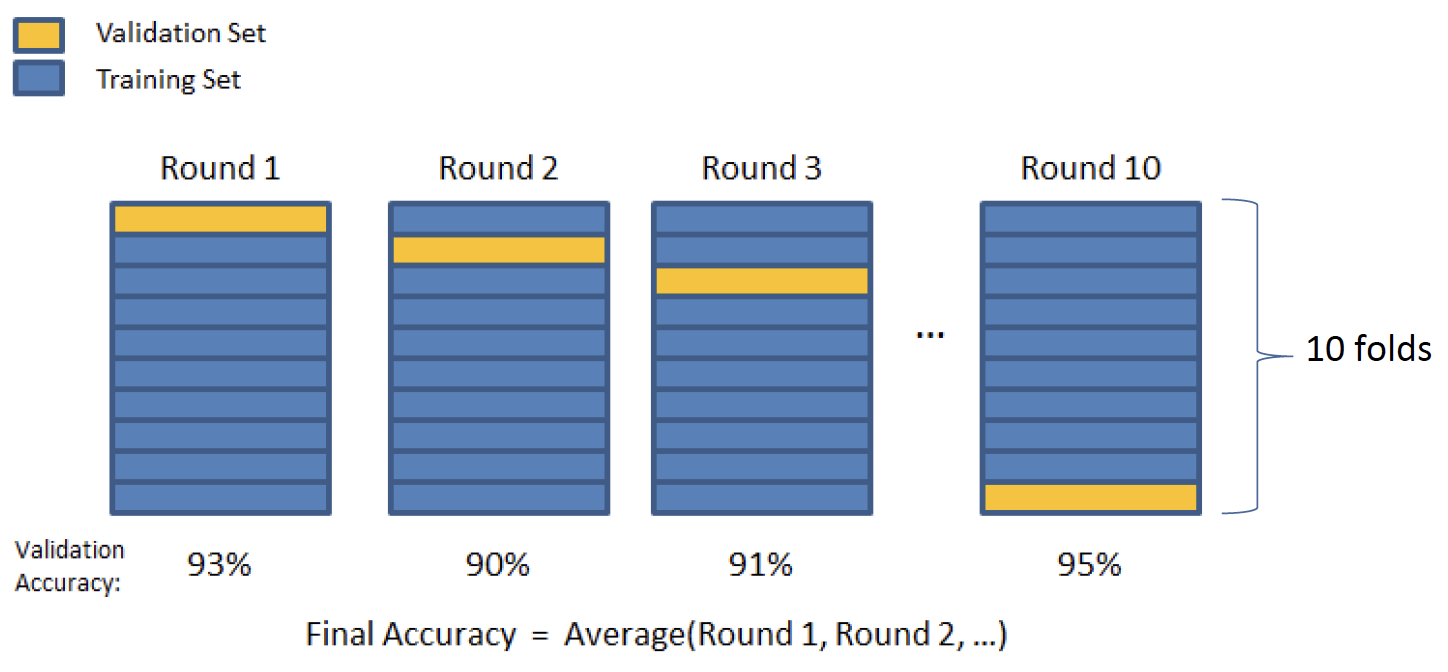
需要定一个 N ,可以选择任何一个大于 2 的整数,一般可以是 5 或者 10。
将数据随机平均分成 N 个 fold。
第一轮,选择第一个 fold 作为 valitation,其他组作为 training,建立模型,并评估,获得了一个 accuracy。
第二轮,选择第二个 fold 作为 valitation,其他组作为 training,建立模型,并评估,获得了另一个 accuracy。
以此类推,共做 N 个 Round。
每轮都选择一个 fold 作为 testing,其余作为 training。
最终生成 evaluation matrix,并且报告 average matrix 作为最终 accuracy。
# Summary
- We always suggest you to use N-fold cross validation, as long as you have enough computational power it doesn’t matter your data is large or small
建议使用 N 倍交叉验证,只要有足够的计算能力,数据大小都无关紧要
因为 Hold-out 方法总归会有 bias 偏倚,数据量大,bias 会小些 - If your computer is not powerful
- Data is large => you can use hold-out
- Data is small => you can use N-fold cross validation
- No fixed rule to say data is large or small. Usually, a data set with less than 500K rows can be considered as small data
没有固定的规则来说明数据的大小。通常,行数小于 500K 的数据集可视为小数据
- Common mistakes: some students run both hold-out
and N-fold cross validation, and report best results.
选择哪种策略的唯一方法是基于数据量的大小
如果数据量小于 500k,直接选择 N-fold cross;数据量大于 500k,但是有大 cpu 或内存,仍然建议 N-fold cross。因为 N-fold cross 更可靠。
- How it works


# General Problem: overfitting 过拟合
- Overfitting Problem
- The model is over trained by the training set;
模型被训练集过度训练;
the performance on the testing set (such as accuracy) is significantly worse than the performance on training set
测试集上的性能(如准确性)明显低于训练集上的性能
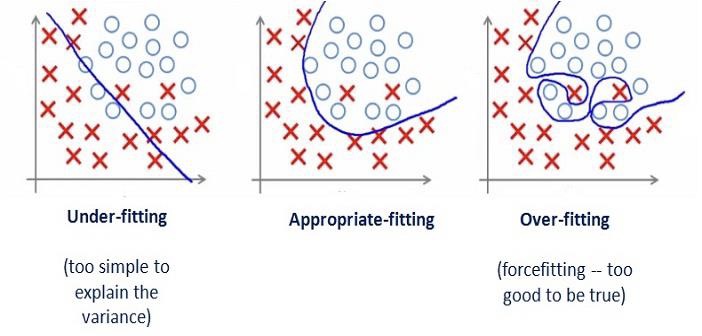
Example of over trained:
过度训练的例子:
students can work on questions on the assignment well, but they may not work well on the questions in the exams.
学生可以很好地解决作业中的问题,但他们可能无法很好地解决考试中的问题。Is there an overfitting problem?
- Linear Regression Models 线性回归模型
- M1: = 96%, MAE = 0.36
- M2: = 98%, MAE = 0.6
Adjust R Square tells you how the model performs on the train data set
MAE tells you how the model performs on the test data set
in the train data set, M2 works better than M1.
in the test data set, M2 works worse than M1
M2 has overfitting problem.
Because theoretically M2 works better than M1 on train data set, so M2 should also works better than M1 on test data set. But unfortunately, the MAE on the test data set is increased. - Classification Models 分类模型
- M1: Accuracy on training = 90%, testing = 85%
- M2: Accuracy on training = 80%, testing = 85%
- M3: Accuracy on training = 85%, testing = 60%
M3 有严重的问题,M1 的情况比较常见,不算严重
不管是哪种模型,都要基于 testing data 出报告,而不应该基于 training data
- Linear Regression Models 线性回归模型
# Classification Algorithms
How to perform classification tasks?
如何执行分类任务
Classification algorithm is the key component in the process
分类算法是该过程的关键组成部分
They are able to learn from training and build models…
他们能够从训练中学习并建立模型…
There are many (supervised) classification algorithms:
- K-nearest neighbor classifier K 近邻分类器
- Naïve Bayes classifier 朴素贝叶斯分类器
- Decision tress 决策树
- Linear/Logistic regression 线性 / 逻辑回归
- Support Vector Machines 支持向量机
- Ensemble classifiers (e.g., random forest) 集成分类器(如 随机森林)
- Neural Networks 神经网络